Introduction
Apache Kafka is an open source event streaming platform proficient at handling events, developed by LinkedIn. It is written in Scala and Java, based on the publish-subscribe model of messaging. It uses TCP network protocol. has good performance and robustness, with the low TCO of a turnkey appliance. In this blog, we will look into MuleSoft Integration with Apache Kafka in order to empower your network and achieve a seamless integration between your Mule app and Apache Kafka.
Architecture
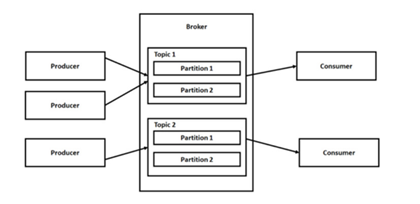
Kafka architecture has producer, consumer and topic
- Producer: Producer publishes message to topic.
- Consumer: Consumer reads messages from topic
- Topic: Events or data in the message system are organised and stored in topics. A topic can have zero or any number of producers likewise a topic is subscribed by zero or any number of consumers.
- Partitions: Topic is divided into a number of partitions . It allows you to split the data in a topic in different partitions and share among different brokers. It allows client applications to both read and write the data from/to many brokers at the same time. When a new event is published to a topic, it is actually appended to one of the topic's partitions. There is no message-id for messages in Kafka. Messages in a partitions are uniquely identified by a number called offset.
Use cases of Kafka:
- Tracking website activities
- Managing operational metrics
- Aggregating logs from different sources, processing stream data
Advantages of Kafka compared to other messaging services
- Kafka is a distributed processing system which can process huge amount of data unlike ActiveMQ which is traditional messaging system
- Highly scalable
- Delivers high throughput. Kafka throughput is 2x - 4x times more than normal messaging systems like ActiveMQ and RabbitMQ.
- Performance won’t degrade with the increase in the number of consumers
- Kafka consumers can re-consume a message from topic by resetting offset to a previous value
- In Kafka, data can be replicated among multiple nodes and therefore is highly reliable
- All messages written to Kafka are persisted and replicated to other brokers for fault tolerance. (We can configure how long messages should be available in Kafka system)
Setup Kafka in Local Machine
For windows download Kafka from the below link and follow the installation steps in the document
https://kafka.apache.org/downloads
Kafka Installation Steps (Mac OS)
- Kafka works only with Java 8
- Kafka also requires Zookeeper to work. Zookeeper is a software developed by Apache, it keeps track of status of the Kafka cluster nodes, Kafka topics, partitions etc.
- We don’t need to install Zookeeper separately. There is an in-built zookeeper in Kafka.
- Install Kafka in mac.
brew install kafka
- Once Kafka is installed successfully we need to start Zookeeper server and Kafka server. Before that you need to modify the server.properties file. If we didn’t change the file, we may face some connection broken issues.
- Go to /usr/local/etc/kafka/server.properties
- Here uncomment the server configuration from
listeners=PLAINTEXT://:9092
to
listeners = PLAINTEXT://localhost:9092
Start Zookeeper
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties
Start Kafka Server
kafka-server-start /usr/local/etc/kafka/server.properties
Create topic
Kafka topic is where Kafka producers (publishers) publish messages. Topic will be listened to by more than one subscriber.
- Topic name: test
- Replication-factor should be less than or equal to the number of nodes in a cluster
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Here test is the name of the topic

Create Producer Console
Now we will create a Producer console for test topic
kafka-console-producer --broker-list localhost:9092 --topic test

Create Consumer Console
kafka-console-consumer --bootstrap-server localhost:9092 --topic test --from-beginning
We can publish messages from producer to topic by writing text in producer console

Subscriber will listen to topic and display the same message in consumer console

The same can be achieved by using Mule Kafka Connector
Steps to setup multi-broker cluster
In the previous step we have created a single Kafka server (node) which is like a cluster with a single broker. Now we will add one more node to the same cluster
For that we need to copy contents of server.properties file inside /usr/local/etc/kafka to a new file server-one.properties in the same location
Now edit the following details in the new file
broker.id=1
listeners = PLAINTEXT://localhost:9093
log.dirs=/usr/local/var/lib/kafka-server1-logs
broker.id property is the unique and permanent name of each node in the cluster. We have to override the port and log directory only because we are running these all on the same machine and we want to keep the brokers from all trying to register on the same port or overwrite each others data.
Now start the new node. We have already started first broker and zookeeper
kafka-server-start /usr/local/etc/kafka/server-one.properties
Create a new topic “cluster-topic“ for this cluster with 2 partitions and replication-factor as 2
--create --zookeeper localhost:2181 --replication-factor 2 --partitions 2 --topic cluster-topic
We can check which are brokers are using this topic by executing the below command
kafka-topics --describe --zookeeper localhost:2181 --topic cluster-topic
And it will give the output something like

Now we will send message from one broker and will check if it is consumed by two brokers in the cluster
Create a producer console
kafka-console-producer --broker-list localhost:9092 --topic cluster-topic
Create two consumer console with different port
kafka-console-consumer --bootstrap-server localhost:9092 --topic cluster-topic
kafka-console-consumer --bootstrap-server localhost:9093 --topic cluster-topic
Send message from Producer console

Message is consumed by both the consumers in cluster

Mulesoft Kafka Connector
Kafka Connectors are ready-to-use components, which can help us to import data from external systems into Kafka topics and export data from Kafka topics into external systems. Connector helps you to interact with Apache Kafka Messaging system and provide seamless integration between mule application and apache messaging system.
Connector category: Select
Operations Available
- Publish: Used to publish message to specified Kafka topic, publish operation support the transactions
- Consume: Used to receive the message from one or more Kafka topic. Consume and Message Listener work in a similar way. Consume require other event source to trigger the flow
- Message Listener: This source supports the consumption of messages from a Kafka Cluster, producing a single message to the flow
- Commit: Commits the offsets associated to a message or batch of messages consumed in a Message Listener
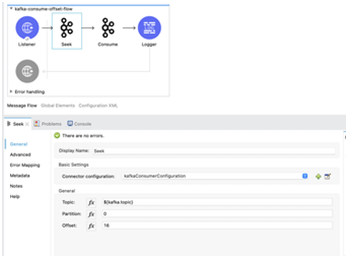
- Seek: Sets the current offset value for the given topic, partition and consumer group of the listener
Steps for Configuring Kafka in Anypoint Studio
- Create a simple mule project kafka-poc
- Import Apache Kafka Connector from Exchange
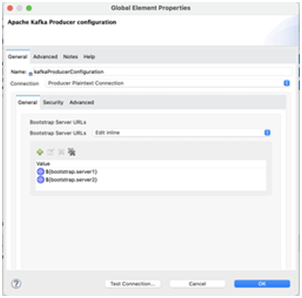
- Add Kafka Producer Configuration in global.xml file
- Note: localhost:9092 and localhost:9093 are the servers where kafka is running
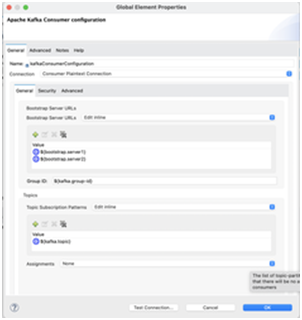
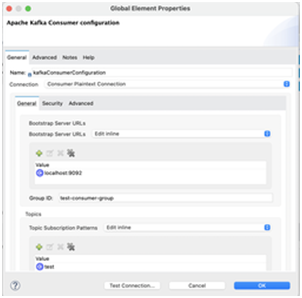
- Add Kafka Consumer Configuration in global.xml
- Bootstrap Server: Kafka cluster servers
- GroupId: default is ‘test-consumer-group’
- Topic value: cluster-topic
- Create 2 flows. One to publish message and second flow to consume message from topic
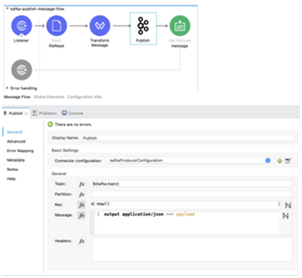
Publish Message Flow
- Publish Component Configuration:
- Topic : topic name
- Key: now() [when message to publish]
- Message: Message that wanted to publish. In the below example we are reading data from a CSV file and publishing it to topic
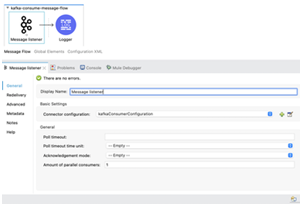
Consume Message Flow
- Message listener is used to consume message
- Once the application is deployed successfully in Anypoint Studio, hit the endpoint to publish message to topic
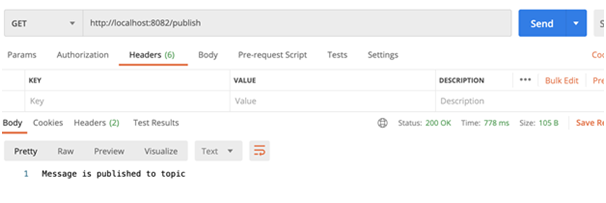
- We can check in both Consumer console to verify the message
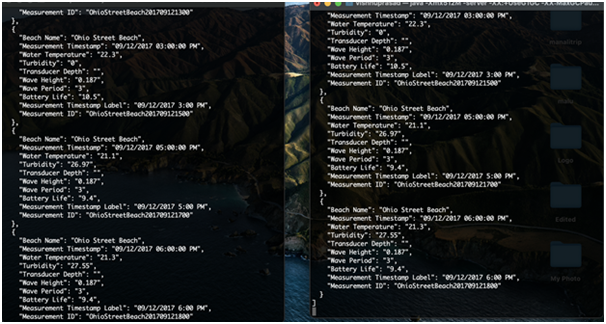
Re-consume message from topic
Kafka consumers can re-consume a message from topic by resetting offset to a previous value. For this we use Seek operation.
Before starting we need to see the current offset position of consumer. For that run the below command
kafka-consumer-groups --describe --group cluster-consumer-group --bootstrap-server localhost:9092

Publish some messages to topic from producer console

And check the offset again

Now the current offset for partition 0 is 18 , with seek we will set the offset back to 16 and will consume the message at that position.
Seek Configuration in Studio
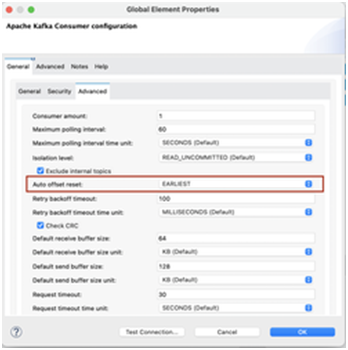
By default auto offset reset in Consumer configuration is Latest. For consuming data from a previous offset we need to change that to Earliest
Deploy the application and hit the endpoint from postman
Anypoint Studio Console

Realtime Examples
Before concluding we will see some examples of organisations where Kafka is being used.
Note: Kafka is used by more than 100,000 organisations
- Adidas: uses Kafka as the fast data streaming platform
- AirBnB: used for exception-handling, event tracking
- Tinder: for notifications, recommendations, analytics
- Uber: for matching drivers and customers, sending ETA calculations, and audit data
- Netflix: Used for real time monitoring, handles over 1.4 trillion of messages per day
- LinkedIn: used for activity stream data and operational metrics, handles 7 trillion messages per day
- Foursquare: used for online messaging
Conclusion
You have successfully integrated MuleSoft with Kafka by publishing message to Kafka topic and re-consume a message from topic.